March 3, 2016
Topic Clusters with TF-IDF Vectorization using Apache Spark
In my previous blog about building an Information Palace that clusters information automatically into different nodes, I wrote about using Apache Spark for creating the clusters from the collected information.
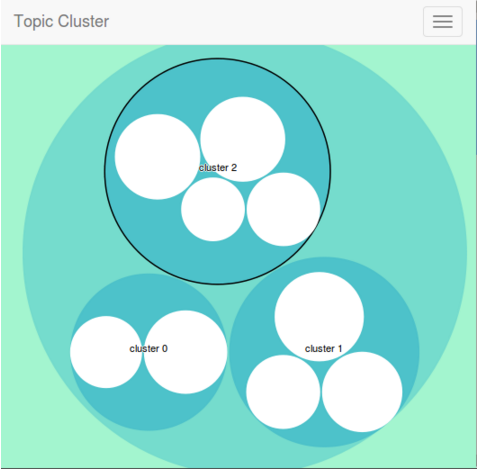
This post outlines the core clustering approach that uses the new DataFrame API in Apache Spark and uses a zoomable circle packing to represent the clusters (using the excellent D3.js). In addition, the common terms and the unique terms at each level of the hierarchy are shown when a cluster or a node is zoomed in. The hierarchy is defined by the overall data set, at each cluster in the data set, and at each data node in a cluster.
In addition to the traditional clustering by machine learning, I have added a “Node Size” attribute which may present a new approach to the organization and presentation of unstructured data such as news or any free text. The “Node Size” attribute is calculated from the unique terms a data node provides to the corpus in addition to the common terms, which allows it to be clustered with similar data nodes.
The thinking behind this approach is if there are some articles that have a common set of words, the one article with more unique words is likely to cover the subject in greater detail than the other ones. In addition, there is a non-deterministic limit for these unique words, beyond which the clustering algorithm will eject it from the cluster. This thinking is further validated by how typical search engines use an inverted documented index to find the most relevant documents for a given search term.
For the media industry, suggesting a particular source of information over other similar sources by using the “Node Size” attribute can be a simpler alternative or even a correlating factor with user trends. I think this is particularly suitable for businesses such as law firms, healthcare, and banking where relevance must be determined from the articles or data sources themselves.
The rest of this post outlines the implementation of the clustering approach.
Data Set
In order to test the effectiveness of the clustering approach, I curated data from different sources on three historical figures: Napoleon Bonaparte, Sir Winston Churchill, and Mahatma Gandhi. Each data point is represented by a file with the following format:
source||||content
source:This is the source URL for the content. For this data set it is the relative path to the file, for example data/churchill-file-1.txt.delimiter:The |||| is the delimiter.content:This is the extracted content from the source. This is just plain text.
In this representation, I have 3 data sources for Napoleon Bonaparte, 2 for Sir Winston Churchill, and 4 for Mahatma Gandhi. The perfect clustering algorithm would create 3 clusters and put the data sources for each historical figure in its own cluster.
Loading the Corpus
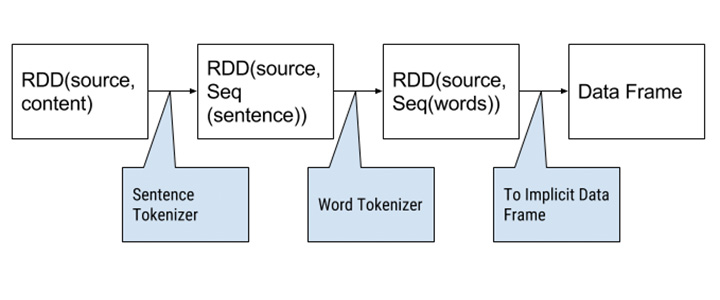
The data set is loaded as a paired RDD with the source as the key and the content as the value. In Spark, an RDD (Resilient Distributed Dataset) is the primary abstraction of a collection of items. Two successive map operations are executed on the values to tokenize the content into sentences and tokenize each sentence into a flat list of words.
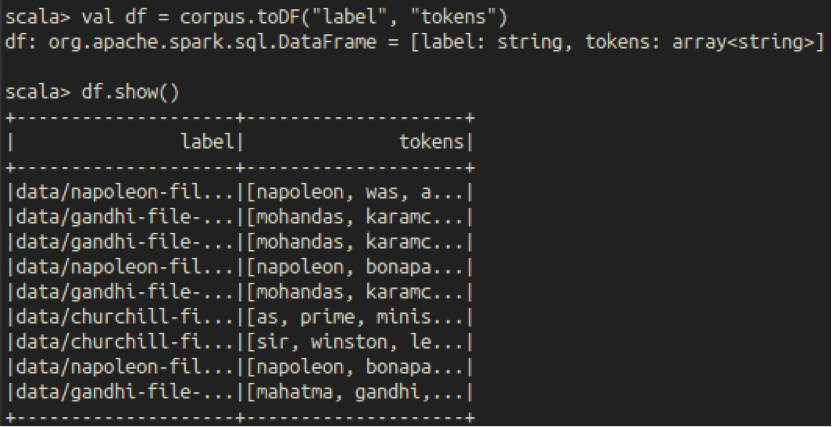
The first data frame is built from this RDD and it has a text label and a sequence of tokens (words). A Data Frame is analogous to an SQL table, which holds multiple columns with labels. Spark can create data frames from multiple sources such as Parquet, Hive, or a Spark RDD. Just like some operations on an RDD, data frame transformations are “lazy” – they are executed on the Spark cluster when Spark is asked to compute the result and this computation is known as a ‘fit’. A fit transforms a data frame into a model, which is used to make predictions. Multiple transformers and models can be chained together (in a directed acyclic graph) to make up a pipeline for machine learning.
The initial data frame has “label” for the source (the paired RDD key) and “tokens” for the words (the paired RDD value).
Data Frame Transformations
A series of transformations are added to the pipeline to add additional columns to the data frame. The transformations can be expressed as a DAG where each node denotes the column added to the frame and a callout is the applied transformation.
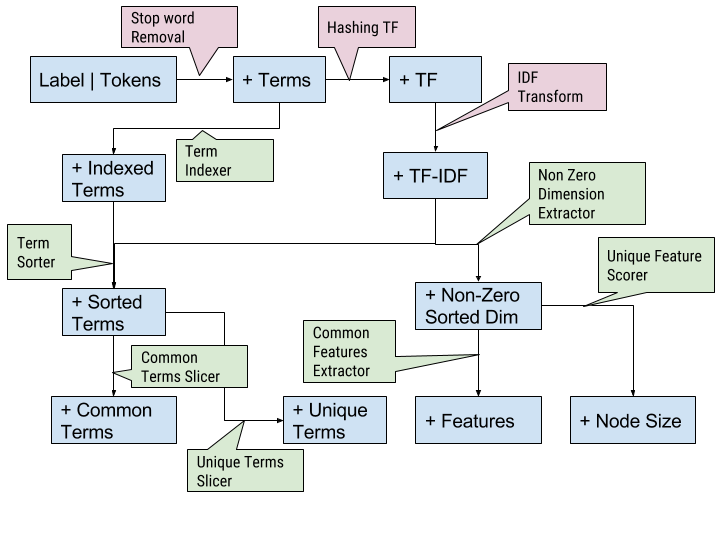
All the transformers in the pipeline marked with a green background are known as “User Defined Transformers” (UDTs) – Spark makes it simple to use the provided transformers as well as to roll your own transformers. I will cover some of the important transformers:
- Hashing TF: This transformer is provided by the Spark machine learning library and it transforms each term (word) to its hash (calculated by a hashing function). The input to this transformer is a sequence of terms and the output is a sparse vector (from the linear algorithm module). A sparse vector stores the indices with active dimensions and the values in each dimension. In this case, each index is the output of the hashing function for the term and the value at the index is the frequency of the term in the data node (document).
- IDF Transform: This Spark-supplied transformer calculates the inverse document frequency of each term. The TF-IDF score for a term that is unique in the corpus is higher than a term that is common in the corpus. Therefore, the lower dimensions of a TF-IDF vector for a document represent its share of common terms in the corpus, while the higher dimensions represent the unique terms.
- Term Indexer, Term Sorter: The Hashing TF and IDF transformers do not maintain a one-on-one mapping with a term. I did not find a built-in way to correlate a TF-IDF value with the term that produced it (backtracking). I needed this backtracking to extract the common terms and the unique terms. The term indexer accepts a sequence of terms, runs each term by the same hashing function as the Hashing TF transformer and maps out a sequence of (
hashed index, term) tuple. The term sorter joins the index from this tuple to the TF-IDF vector to produce a sequence of (TF-IDF score, term) tuples. - Common Features Extractor: This transformer operates on the TF-IDF vector and extracts the lower dimensions of the sparse vector to return a dense vector. This transformation is actually the link to the final clustering transformation.
A Data Frame can be queried for its schema. Once the transformations have been added (not necessarily applied), you can see the schema:
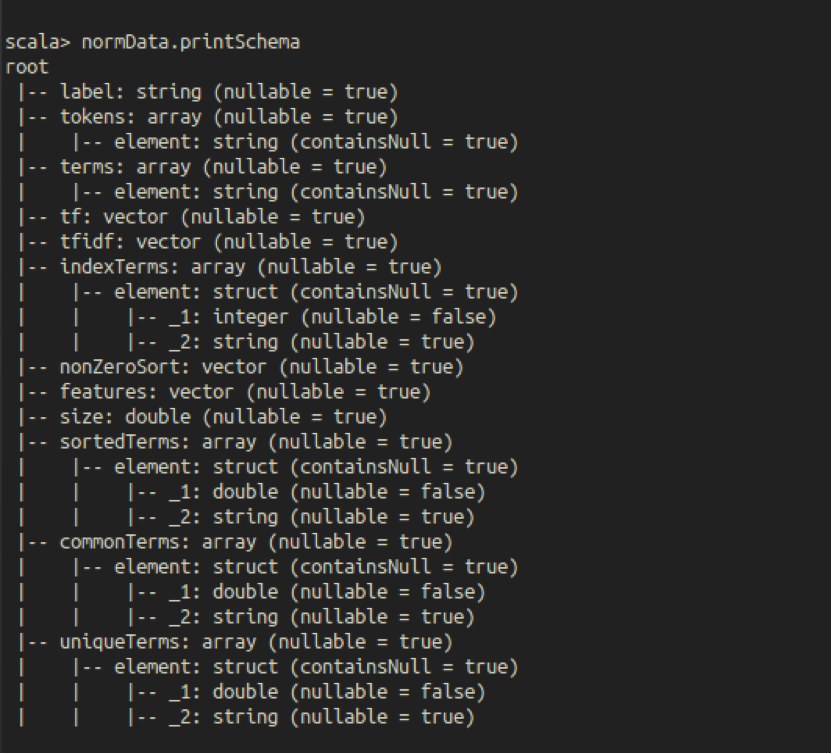
KMeans Clustering
The Spark machine learning library has a bunch of clustering algorithms. While KMeans is probably the simplest to understand and implement, it is also quite effective and is put to use in lots of applications. KMeans is also implemented as a transformer that takes the Features column from the Data Frame and predicts the clusters in an output column which we call – wait for it – “Cluster”! Once the transformation (actually the pipeline) is applied, the new column reflects the data we were working towards:
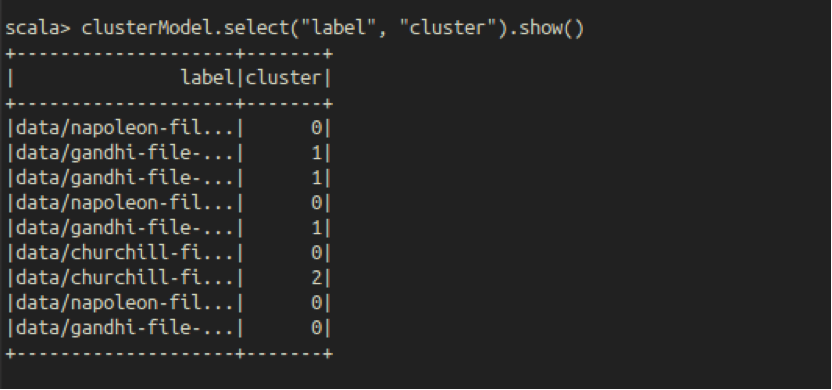
The clustering algorithm produces 3 clusters and almost gets it right – one data node for Mahatma Gandhi is clustered with all the Napoleonic data nodes (the irony of it!), rest of the data nodes are clustered correctly.
The KMeans clustering algorithm needs to be told the number of clusters to create. If you ask it to create too few, dissimilar items will appear in the same cluster; too many and similar items will land up in different clusters. The current implementation uses the “Rule of Thumb” to calculate the number of clusters (k):
![]()
where n is the number of documents to be clustered. In addition, the current implementation caps ‘k’ to 1000.
Future Scope
There are quite a few ways in which the clustering approach can be improved or augmented:
- For this study, I curated the data manually. In order to automate this, we will need a clever way to filter out the noise to produce meaningful tokens. While this can probably be addressed at the first level by using a series of filtering regular expressions, another way would be to work with a corpus specific stop word list.
- If you look at the list of unique and common terms you will notice terms like “called” and “acted” – non-root forms of the words. We would probably get better results if the term and document frequencies are calculated on word-stems by applying a lemmatizer.
- For some corpora, it might be beneficial to perform a part of speech tagging to identify interesting words.
- At the moment, the number of dimensions analyzed for common and unique terms are fixed. It will be useful to treat these as dynamic variables as a function of the document sizes.
- The KMeans implementation from Spark uses Euclidean distance as a distance measure between the TF-IDF vectors. I think a cosine similarity model would be a better fit for analyzing similarity between documents. I did not find a way to influence the KMeans transformer to use a cosine distance measure; a future implementation could make use of a custom transformer.
- The number of clusters to create can be determined by the “Elbow Method” instead of applying the rule of thumb.
Apart from the core algorithm, it would be necessary to evolve this into a system which ingests data and persists the clustered models.