November 5, 2015
The Future of Alternative Mobile Data Input
Smart mobile devices have become ubiquitous in our lives and they are also seen as a solution in non-tech business areas. Any business that needs data input has also begun considering mobile devices.
We have been observing an emergence of new use-cases for mobile devices: usage for data input in environments with low computer skills personnel, like plumbers, construction workers, or in environments where traditional interaction with such mobile devices is uncommon. I am thinking about environments where people cannot use their hands to interact with a keyboard or touch screen, or where the noise would prevent them from using voice commands.
The most common alternatives to touch screens, voice recognition and gesture control, are evolving fast, and new solutions are becoming available very quickly. These alternative mobile data input methods allow for the usage of computer technology in some new areas where, due to technical limitations, it was not possible before.
As mobile devices evolve at the benefit of lower costs, better performance, and affordable internet connectivity, and new technology emerge for interaction, we see a potential to address new markets by offering an alternate solution to input data in new ways into already available mobile devices. But how far are these technologies from production usage?
While there are several solutions targeted for gesture control (such as Microsoft Kinect, Google SOLI, MYO Gesture Control Armband, and Leapmotion), none of them are usable directly from a mobile phone yet. There is quite accurate object recognition when using the mobile phone camera, but the gesture recognition is not production-ready.
Se we looked to test voice recognition and solutions based only on the capabilities of mobile phones without using any other external device. We created a prototype for one common use-case: consider a mobile application (Android and iOS) where you can navigate through menu items and introduce alpha-numeric data. All of the operations should be possible by both mobile touchscreen and voice commands, with a preference to a solution that is able to work in an offline mode.
In order to avoid continuously listening for voice commands, we will use face detection to start interpreting voice commands. When the app detects a human face, it will launch the startup screen, where you can see several cards and select from them using a voice command. Each card will take you to a screen where you can either pick an option from a drop-down menu or introduce text in different text boxes (like name, email, etc.). Then you should be able to save the introduced data and navigate back to the startup screen. Each action should be able to be fulfilled using the mobile touchscreen or voice commands.

In order to reach the main screen, you can either touch the screen or sit in front of the camera.

Any option can be selected by touching the corresponding area or saying the corresponding number aloud as a voice command.
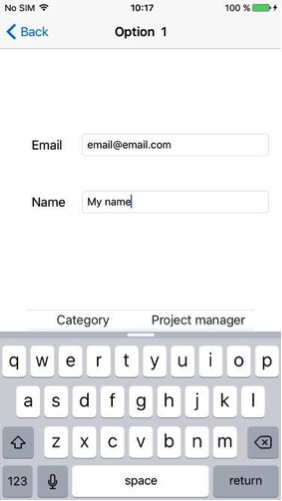
You can select the fields and dictate content with voice commands.
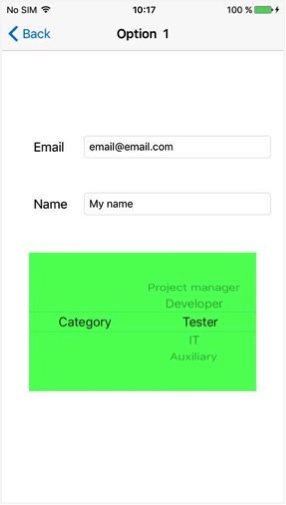
Select options from the spinner and navigate between the screens using voice commands.
For implementing this proof of concept, we tested voice commands and gesture and face recognition on several software libraries that can enhance your user experience on your mobile device.
Below is what we tested, and the conclusions we reached.
Image, Gesture, and Face Recognition
- Open-Source Computer Vision (OpenCV): We found it to be immature, and occasionally blocking and introducing a lot of lag on image recognition. We think it’s not yet usable in a real world mobile application
- Face detection native API support from Android and iOS: We found that this works well and with reliable accuracy. We used it to automatically launch the startup screen and voice recognition when detecting a human face
- Gesture Deep Belief SDK: We found this to be available offline, as well as on Android. It allows for an app to be trained on positive and negative samples. We could use it for gesture recognition, and we used it to recognize hand positions and different objects such as mugs, keyboards, etc.
Voice Assistants on Android
- PocketSphinx: This is a speaker-independent continuous speech recognition engine that utilizes Carnegie Mellon University’s open-source large vocabulary. We found that it works offline, and that it’s both easy to use and to set up grammar. It listens to everything and tries to match to something in the grammar used vocally. We ended up using this solution due to the offline support offered.
- Android Speech API: We found that this works only in offline mode, which you need to tap to go into voice commands. This works better than PocketSphinx on recognizing commands.
- iSpeech: This works only in an online mode. In the two days we spent working with it, we couldn’t make it recognize a command. Not even their demo was responsive.
Voice Assistants on iOS
- OpenEars: We found that this works offline and allows for customized grammar. This is an open-source engine that will listen continuously for speech on a background thread. We used arrays and coupled words, and found that it works best with fluent English with clear breaks between words. We ended up using this due to its offline support.
- Dragon Mobile Assistant: This works online and is based in Nuance. It has good reliability, and is also used by Siri.
- iSpeech: This works online, but it has an inflexible API and needs a time to be given for listening and restarting after each command.
While the alternative voice commands were appreciated by our recipients, the touchscreen should still be available and will remain as the main interface for mobile applications for a while. Even if the voice or gesture controls are not yet at that production-ready maturity, we will see that in the next couple of years, future mobile apps incorporating alternative ways to interact with the user, as well as allowing a more complex experience and reaching new usability areas.